


.png)
Lambda Labs has carved out a solid reputation in the AI infrastructure space, offering specialized GPU cloud services tailored for deep learning and machine learning workloads. Since its founding in 2012, the company has aimed to reduce the high cost of training large-scale AI models—something its founders experienced firsthand while working with more traditional providers like AWS.
But as the AI ecosystem evolves at breakneck speed, so do the demands on infrastructure. Developers, researchers, and ML ops teams now require greater flexibility, more transparent pricing, and access to a wider range of hardware configurations to meet their ever-changing needs.
To help navigate this shifting landscape, we conducted a deep dive into alternatives to Lambda Labs—gathering insights from Reddit threads, user testimonials, developer communities, and third-party review platforms. We looked for platforms that not only match Lambda’s performance but also excel in areas like specialized GPU availability, cost predictability, and support for advanced customization.
In this guide, we unpack ten leading alternatives to Lambda Labs in 2025—each vetted through hands-on research and real-world feedback.
Whether you’re looking to scale more efficiently, reduce costs, or gain access to unique GPU options, this list offers a clear starting point for your next move.
What to Look for in a Lamba Labs Alternative?
The selection of a suitable GPU cloud provider necessitates a careful evaluation of several critical factors.
With a lot of options available, it’s essential to evaluate several critical factors to ensure you choose a provider that aligns with your computational needs, budget, and workflow requirements. Below is a comprehensive listicle outlining these key considerations:
- GPU Types and Performance: Look for high-end options like NVIDIA A100 or H100, ensuring excellent computational throughput and memory bandwidth for optimal AI training and inference.
- Transparent Pricing Structures: Compare hourly, reserved, and spot pricing models, and be mindful of hidden fees such as data transfer, storage, and additional service charges.
- Scalability and Management: Choose providers that offer easy resource scaling, a user-friendly interface, and robust APIs to streamline instance management and adapt to fluctuating project needs.
- Ease of Use and Documentation: Prioritize platforms with intuitive interfaces and comprehensive documentation to reduce the learning curve and enhance team productivity.
- Storage Solutions and Data Transfer: Evaluate the storage capacity, performance, and costs, while considering how data transfer frequency and location might impact overall expenses.
- Network Infrastructure: Ensure the provider offers high-bandwidth, low-latency connectivity crucial for distributed training and real-time AI applications.
- Security and Compliance: Verify that robust security measures—such as encryption and strict access controls—are in place, along with adherence to industry compliance standards.
- Customer Support and Community: Look for responsive support, extensive tutorials, and an active community to help troubleshoot issues and foster innovation.
By carefully considering these factors, you can select a GPU cloud provider that not only meets your current needs but also scales with your future AI ambitions.
Top 10 Lambda Labs Alternatives
To provide a clearer understanding of the options available, the following sections detail ten prominent public cloud providers that are the best alternatives to Lambda Labs for AI and machine learning workloads in 2025.
1. Runpod.io

Via RunPod.io
Runpod.io is a top choice for individual developers and small teams seeking cost-effective GPU compute solutions that deliver the computational power needed for deep learning and language models.
Its flexible marketplace meets a wide range of needs—from budget-friendly consumer GPUs like the 1080 Ti to high performance GPUs such as the 4090.
With near-instant pod spin-ups and support for frameworks like PyTorch and TensorFlow, Runpod.io lets you focus on your models rather than the hardware.
Ready to give RunPod.io a shot? Get started today!
Key Features:
- Access to thousands of GPUs across 30+ regions
- Preconfigured templates and support for custom containers
- Lightning-fast cold starts (sub-250ms)
- Serverless autoscaling and high-throughput network storage
- Enterprise-grade security and compliance (SOC2, HIPAA)
Runpod.io Limitations:
- May offer less customizability than larger providers
- Regional GPU Server availability can vary
Runpod.io Pricing:
- Flexible pay-as-you-go rates starting as low as $0.16/hr
- Multiple tiers (Secure and Community Cloud)
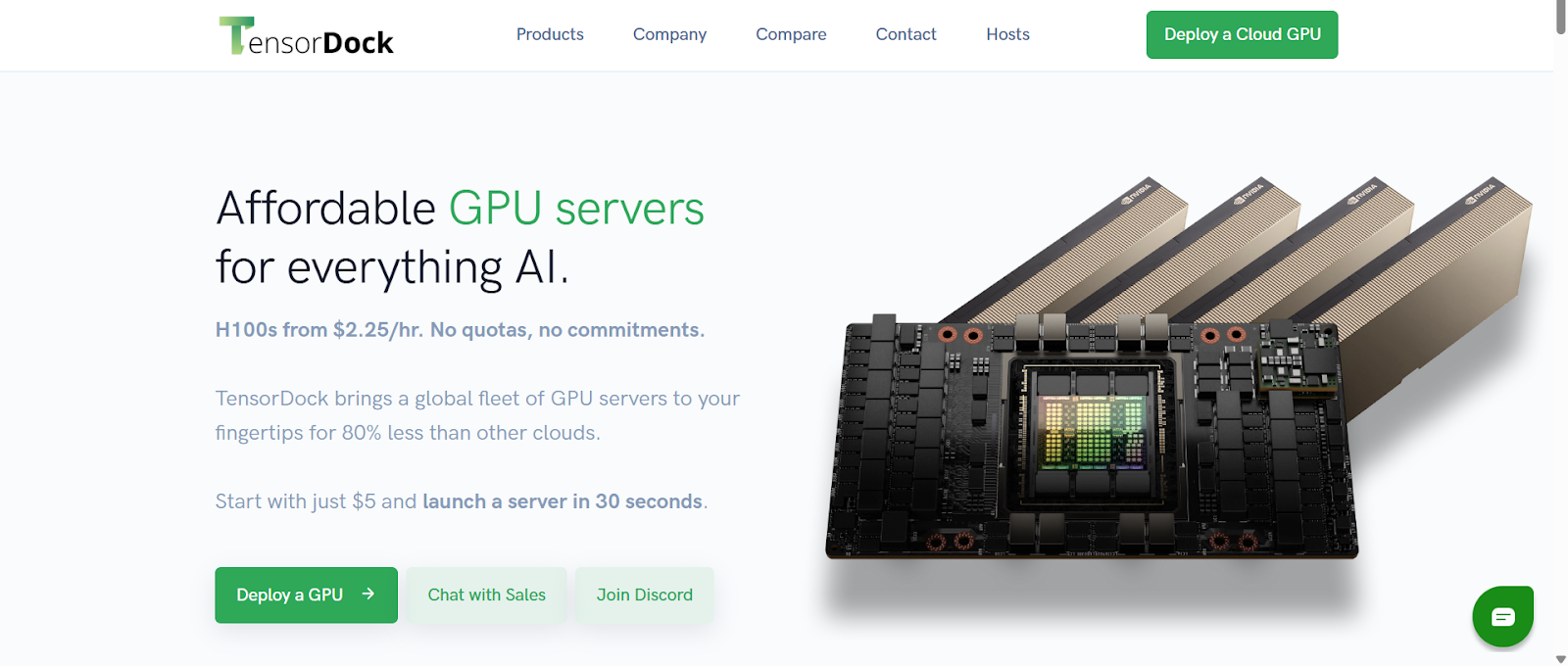
2. TensorDock
Via TensorDock
TensorDock is well-suited for cost-sensitive projects with moderate computational demands, making it an attractive option for academic researchers and independent machine learning engineers.
It offers a flexible, on-demand GPU cloud environment that allows users to tailor their resource allocation precisely through an a la carte billing system.
With an extensive selection of 44 GPU models and a global presence spanning over 100 locations, TensorDock enables users to deploy various workloads without long-term commitments or imposed quotas.
Its pay-as-you-go pricing model ensures that you only pay for the resources you use, providing a balanced mix of performance and affordability. This approach makes it a practical choice for projects where computational needs can vary, and cost efficiency is a primary concern.
Key Features:
- Wide selection of GPU models (44 available)
- Global network with 100+ locations
- A la carte billing system for customizable resource allocation (GPU, RAM, vCPUs)
- Flexible, pay-as-you-go pricing model (Uses optimal computational resources)
- No quotas on GPU usage
TensorDock Limitations:
- Limited brand recognition compared to larger cloud providers
- May lack a comprehensive enterprise support ecosystem
TensorDock Pricing:
- Offers a straightforward pay-as-you-go model with a $5 initial deposit
- NVIDIA H100 SXM5 instances start at $2.25/hr (advertised as an industry-low rate)
- Consumer GPUs from $0.12/hr, and CPU-only servers from $0.012/hr (best competitive prices)
3. CoreWeave

Via CoreWeave
CoreWeave is geared toward high-performance computing (HPC) and demanding AI/ML workloads, providing a “no-compromises” cloud computing solutions optimized for large-scale training and inference.
Its focus on top-tier NVIDIA GPUs—including the latest Blackwell (GB200 NVL72) instances—positions it as an attractive choice for enterprises and research labs that require cutting-edge performance.
Users benefit from Kubernetes-native environments, automated cluster health lifecycle management, and flexible storage options, which streamline resource provisioning and help maximize throughput.
This approach is well-suited for organizations seeking robust infrastructure that can handle complex AI pipelines, scale on demand, and offer competitive pricing on high-end GPUs.
Key Features:
- Access to NVIDIA GB200, H100, GH200, and other top-tier GPUs
- Kubernetes-native platform with managed services (Slurm on Kubernetes)
- Enterprise-grade security and compliance (SOC2, ISO 27001)
- 30+ data centers for global availability and low-latency connectivity
- Free egress and data transfer within the CoreWeave environment
CoreWeave Limitations:
- Setup may be more complex for smaller teams or less technical users
- Focus on HPC/AI workloads may mean fewer out-of-the-box features for general-purpose cloud tasks
CoreWeave Pricing:
- On-demand GPU instances (e.g., NVIDIA HGX H100 at $49.24/hr)
- On-demand CPU instances for supporting AI pipelines
- Discounts of up to 60% for reserved capacity
- Storage from $0.07–$0.11/GB/mo, with free egress and IOPS
- Free NAT gateway, VPC, and data transfer within CoreWeave
4. Paperspace

Via Paperspace
Paperspace is a strong option for mid-to-high complexity machine learning projects, making it a favorite among academic researchers and independent ML engineers.
It offers a balanced combination of robust performance and ease of use, allowing users to focus on building and training models rather than managing complex infrastructure.
Paperspace is now a part of DigitalOcean and features an updated interface and streamlined workflows designed to simplify resource management.
The platform supports a variety of machine learning tasks with flexible scaling options—both vertical and horizontal—so resources can be adjusted as project needs evolve.
This makes Paperspace one of the favorite cloud computing platforms well-suited for users who require efficient, on-demand GPU compute with clear and flexible pricing structures.
Key Features:
- Robust performance for diverse ML tasks
- Flexible pricing models, including pay-as-you-go
- Smooth vertical and horizontal scaling
- Integration with DigitalOcean’s developer platform
- Pre-configured templates for rapid deployment
Paperspace Limitations:
- May not offer the extensive enterprise features of AWS or Azure
- Fewer integrated services compared to larger cloud providers
Paperspace Pricing:
- Flexible, pay-as-you-go model with per-second billing
- Competitive GPU Cloud rates (e.g., H100 around $2.24/hr with specific commitments)
- Options available for various GPU and CPU configurations
5. AWS SageMaker

Via AWS SageMaker
AWS SageMaker is an ideal choice for enterprise-grade machine learning, offering a comprehensive, fully managed platform for building, training, and deploying models at scale in the cloud computing industry.
It’s particularly well-suited for organizations deeply integrated into the AWS ecosystem that need robust security, scalability, and a full suite of ML tools—from data preparation and labeling to automated model tuning and deployment.
Key Features:
- Integrated development environment (SageMaker Studio) for end-to-end ML workflows
- Built-in algorithms and support for custom models
- Automatic model tuning and hyperparameter optimization
- One-click training and deployment with scalable endpoints
- Enterprise-grade security and compliance as part of AWS
AWS SageMaker Limitations:
- Complex setup with a steep learning curve for newcomers
- Premium pricing can be high for smaller-scale projects or underutilized features
- Extensive feature set may be overwhelming for users with simpler needs
AWS SageMaker Pricing:
- Premium, usage-based pricing across training, inference, and storage services
- Flexible instance options including on-demand, reserved, and spot pricing
- Costs vary widely based on resource consumption and chosen features
6. Google Cloud AI Platform (now Vertex AI)

Via Vertex
Another Lamba Labs alternative is from the Google Cloud Platform.
Vertex AI is ideal for users who need advanced machine learning tools and are already integrated within the Google Cloud ecosystem.
It excels at leveraging pre-trained models, APIs, and innovative generative AI capabilities, making it a strong choice for enterprises and research teams looking to streamline model development, training, and deployment in a unified environment.
Key Features:
- Comprehensive suite of advanced ML tools and a vast library of pre-trained models
- Seamless integration with other Google Cloud services for unified data and AI workflows
- Access to cutting-edge generative AI models (e.g., Gemini) and AutoML capabilities
- Built-in MLOps tools for efficient model management, evaluation, and monitoring
- Cost-effective solutions for specific use cases compared to other major providers
Google Cloud AI Platform Limitations:
- Complex setup and navigation, which may be challenging for users needing only basic GPU compute
- Premium pricing can be a concern for smaller-scale projects that do not fully leverage its advanced features
Google Cloud AI Platform Pricing:
- Flexible, pay-as-you-go model billed in 30-second increments based on training, prediction, and storage usage
- Costs vary by machine type, accelerator usage, and region, with additional management fees for services like pipelines and model monitoring
- Generative AI tasks are priced per 1,000 characters processed
- A detailed pricing calculator and custom quotes are available to help tailor costs to enterprise needs
7. Microsoft Azure Machine Learning

Via Azure
Microsoft Azure Machine Learning is ideal for organizations that demand robust, enterprise-grade ML services, especially those leveraging hybrid cloud environments and the broader Microsoft ecosystem.
As part of the Azure AI Foundry, it delivers an all-in-one toolkit to streamline the entire ML lifecycle—from data preparation on Apache Spark clusters (integrated with Microsoft Fabric) to automated model training and prompt engineering with prompt flow.
It excels at building business-critical models at scale by providing a comprehensive model catalog featuring offerings from Microsoft, OpenAI, Hugging Face, Meta, and Cohere. This enables users to fine-tune and deploy state-of-the-art models seamlessly.
Coupled with advanced AI infrastructure that includes specialized GPUs and InfiniBand networking, Azure ML is also built on a foundation of robust security and compliance, backed by a $20 billion cybersecurity investment, making it an excellent alternative for enterprises seeking dependable, scalable, and secure ML solutions.
Key Features:
- Complete ML lifecycle toolkit including data preparation, automated ML, and prompt flow
- Access to a diverse model catalog from Microsoft, OpenAI, Hugging Face, and more
- Specialized AI infrastructure with advanced GPUs and InfiniBand networking
- Seamless integration with Microsoft enterprise products and robust security
Microsoft Azure Machine Learning Limitations:
- A learning curve exists for users new to Azure.
Microsoft Azure Machine Learning Pricing:
- Flexible, usage-based pricing that charges only for compute resources during training and inference.
8. Vast.ai

Via Vast.ai
Vast.ai is another alternative to Lambda Labs for users prioritizing cost savings and flexibility in GPU compute environments.
It is designed for developers, researchers, and organizations that need extremely low-priced GPU compute resources while being comfortable with a self-managed infrastructure.
Operating as a decentralized marketplace, Vast.ai allows individuals to rent out idle GPUs at prices that are significantly lower than traditional cloud providers.
This platform is ideal for those willing to work with spot instances, even if it means accepting occasional interruptions in compute availability. Its affordability and bidding system make it an attractive option for cost-conscious AI workloads.
Key Features:
- Decentralized marketplace for renting idle GPUs
- Offers on-demand and interruptible spot pricing options
- Powerful search console with CLI support for automation
- Real-time bidding system for additional cost savings
- Significant cost reductions compared to traditional cloud providers
Vast.ai Limitations:
- Reliability and uptime can vary due to the spot instance model
- Requires advanced technical expertise for optimal setup and management
Vast.ai Pricing:
- Prices are calculated per GPU; for multi-GPU instances, the cost is divided by the number of GPUs on the instance.
- Example rates: RTX 4090 ranges from $0.24 to $0.60 per hour and H100 SXM from $2.13 to $2.67 per hour.
9. DigitalOcean Functions

DigitalOcean is ideal for developers and small-to-medium teams seeking a simpler, more predictable cloud experience without the complexity of major providers.
It caters well to smaller-scale AI/ML projects and web applications, offering both GPU-enabled Droplets and serverless DigitalOcean Functions.
For event-driven workloads and microservices, DigitalOcean Functions provide a serverless execution environment that automatically scales with demand, ensuring cost predictability as you only pay for actual usage.
This dual approach empowers developers to choose the best fit for their project needs—whether that means self-managing a virtual machine for more control or leveraging serverless functions for rapid, on-demand execution.
Key Features:
- GPU Droplets: Simplified VM management with predictable pricing, ideal for compute-intensive tasks.
- DigitalOcean Functions: Serverless, event-driven execution with per-use billing and automatic scaling.
DigitalOcean Functions Limitations:
- Limited range of GPU options compared to specialized AI cloud providers.
- Functions have restrictions in execution time and resource allocation for very heavy workloads.
DigitalOcean Functions Pricing:
- DigitalOcean Functions uses a pay-as-you-go model with no upfront costs; you’re only billed for active function execution.
- Each account benefits from a free monthly allowance of 90,000 GiB-seconds of compute, with any additional usage billed at $0.0000185 per GiB-second.
10. AWS Lambda
![][image10]
Via AWS Lambda
AWS Lambda is among the major cloud providers for developers and organizations looking to run code without the burden of managing servers or clusters.
It excels in handling a variety of workloads—from web applications and real-time data processing to backend services and machine learning preprocessing.
With Lambda, you simply upload your code as a ZIP file or container image, and it automatically allocates the necessary compute resources in response to incoming events.
This service supports multiple programming languages, including Node.js, Python, Java, Go, and more, which makes it versatile for different development environments.
Lambda integrates seamlessly with a wide array of AWS services such as S3, DynamoDB, Kinesis, and SNS, enabling the construction of robust event-driven architectures.
Its built-in scalability, automatic resource management, and fine-grained billing (in 100ms increments) make it particularly effective for applications with unpredictable or variable workloads, all while offering a generous free tier.
Key Features:
- Automatic scaling and resource management
- Multi-language support and container image deployment
- Deep integration with AWS services (S3, DynamoDB, Kinesis, SNS)
- Granular billing in 100ms increments and a generous free tier
AWS Lambda Limitations:
- Cold start latency can affect performance
- Maximum execution time of 15 minutes per function
- Limited control over the underlying infrastructure
AWS Lambda Pricing:
- Usage-based pricing with a free tier (1M free requests and 3.2M free seconds monthly)
- Billed in 100ms increments
Wrapping Up
Every platform on this list brings something valuable to the table—whether it’s unique hardware, regional availability, or pricing structures that suit specific use cases. The best choice ultimately depends on your team’s needs, budget, and the complexity of your AI workloads.
That said, we’d be remiss not to highlight RunPod.io.
We built it to solve many of the challenges we experienced firsthand—whether that’s unpredictable costs, scaling headaches, or limited access to high-performance GPUs. RunPod’s infrastructure is purpose-built for deep learning teams who need speed, reliability, and flexibility—without overcomplicating the process.
So while we absolutely recommend exploring all the platforms mentioned, if you’re looking for a solution that just works for demanding AI tasks, we think RunPod is well worth your consideration.

